










IMAGEBINDにより、複数の異なるモダリティを結びつけることが可能になります。
異なるモダリティからの埋め込みを自然に追加することで、それらの意味が複合されます。さらに、事前学習済みのDALLE-2デコーダと組み合わせることで、音声から画像を生成することができます。
ImageBindとは?
| 公式サイト | https://imagebind.metademolab.com/ |
| FT/NFT | なし、$Zuck bucks? |
| チェーン | non |
| 初期コスト | TBA |
| 運営 | META |
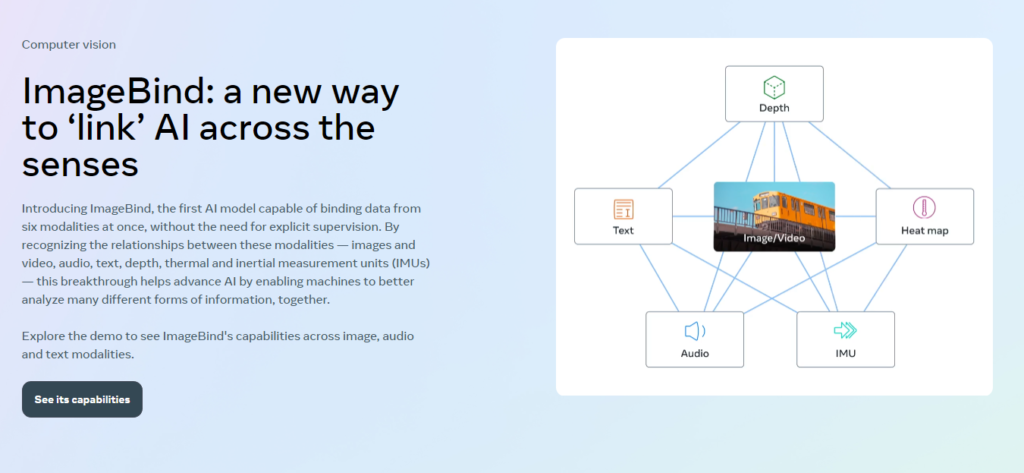
IMAGEBINDは、画像を中心に6つのモダリティ※の共通埋め込みを学習する手法です。
この手法により、クロスモーダル検索や算術的な構成、音声から画像生成などの新しい機能を提供することができます。
また、従来の教師ありモデルを上回るエマージェントなゼロショット認識タスクの最新技術を実現し、ビジョンモデルの評価に新たな手法を提供することができます。
※モダリティとは、話している内容や聞き手に対する話し手の判断や態度に関する言語表現の概念体系です。また、医療用画像における撮影手段のことを指す場合もあります。心理学では、視覚・聴覚・触覚・味覚などそれぞれの感覚器による感覚を指す場合もあります。
ImageBindの特徴は?
- 複数種類のコンテンツのクロス学習
- 人間のような個別の刺激に対する感情表現
- 天下のMeta社製
IMAGEBINDは、複数の種類の画像ペアデータを活用して、1つの共有表現空間を学習する手法であり、クロスモーダル検索、算術的な構成、画像内の音源検出、音声入力に基づく画像生成などの様々な合成タスクに使用することができます。
また、音声、深度、熱、IMU読み取りなど4つの新しいモダリティにおいて強力なエマージェントなゼロショット分類および検索性能を示し、大規模なビジョン・ランゲージ・モデルを初期化することも可能です。
ImageBindの初期コストは?
TBAです。テスト段階では無料ですが、正式ローンチ後に課金されるかも知れません。
ImageBindの運営は?
天下のMeta社です。
ImageBindの始め方は?
2023年5月時点でDEMOが公開されていますが実際の操作はできません。
DEMOページ:https://imagebind.metademolab.com/demo
ImageBindの使い方
Image to Audio
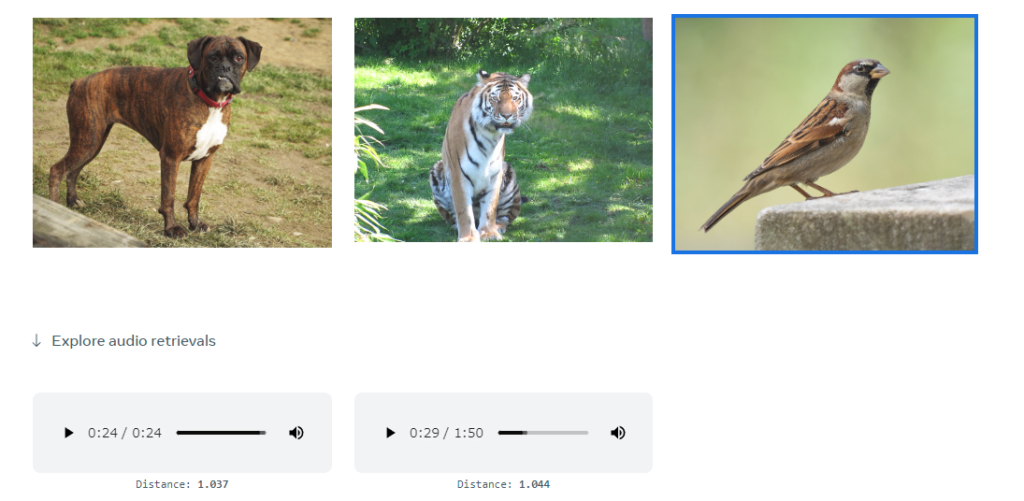
イメージをアップロードして音を再現します。例えば犬や虎、鳥といった画像から鳴き声を表現します。
Audio to Image
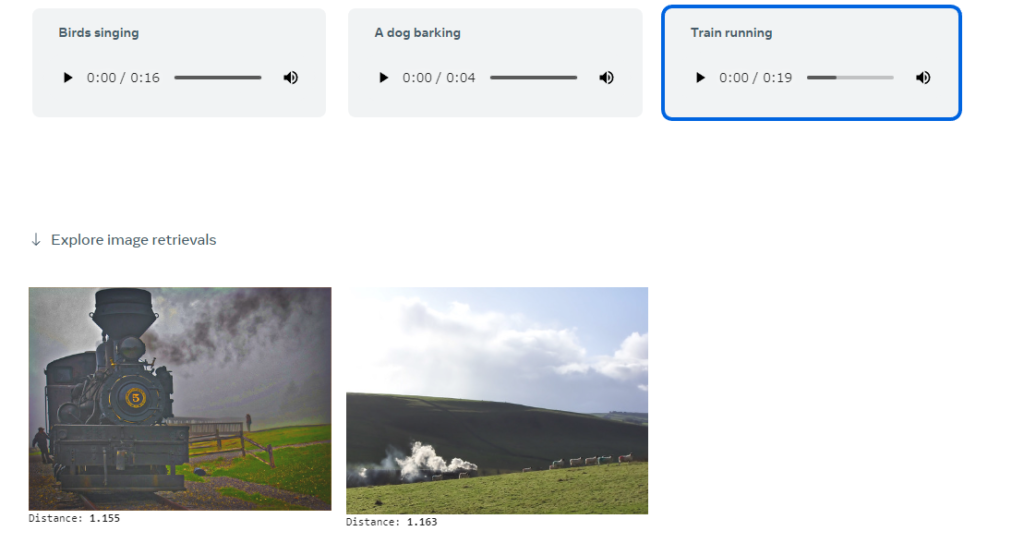
音から画像を生成します。
上記は列車が走る音から「蒸気機関車」を表現しました。
Text to Image&Audio
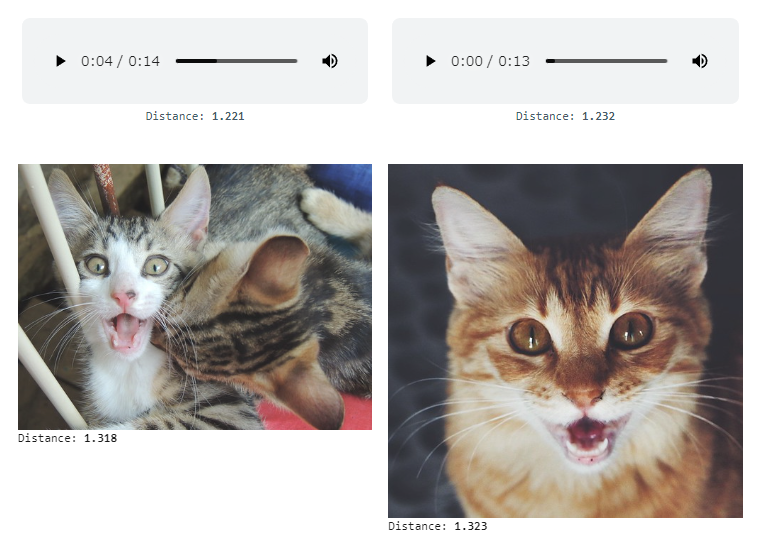
テキストから画像と音声を生成します。既出のツールの複合的使用法です。
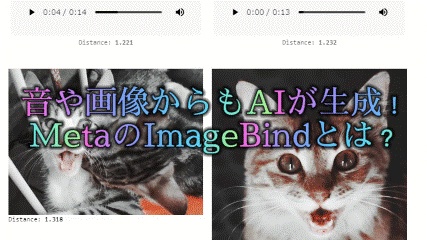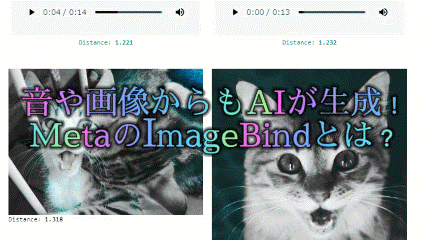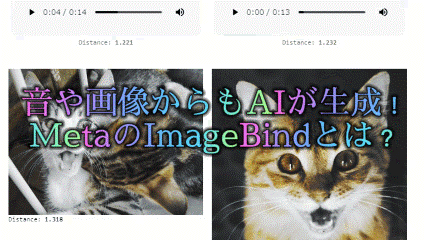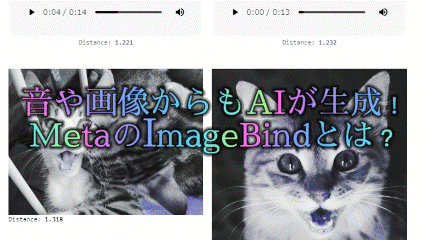
Audio & Image to Image
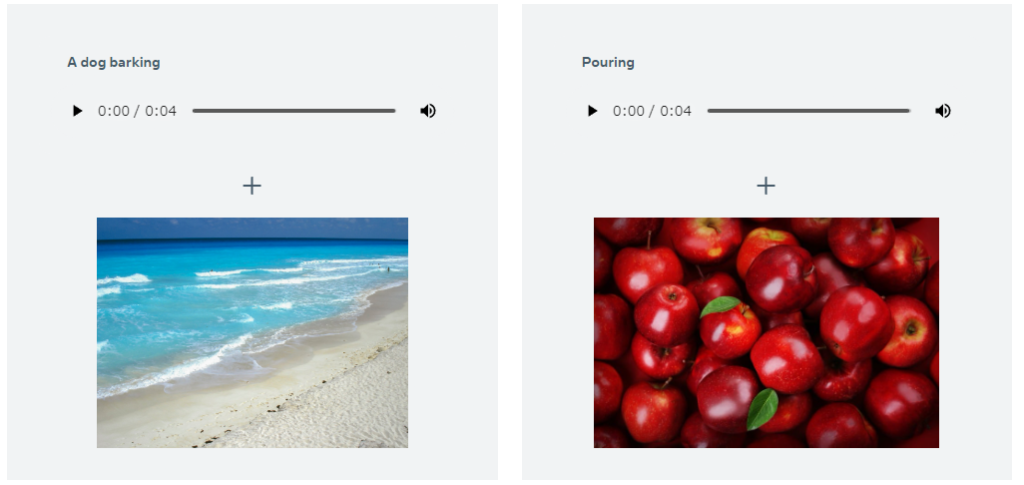
音とイメージからより具体的な画像を生成します。
Audio to Gererated Image
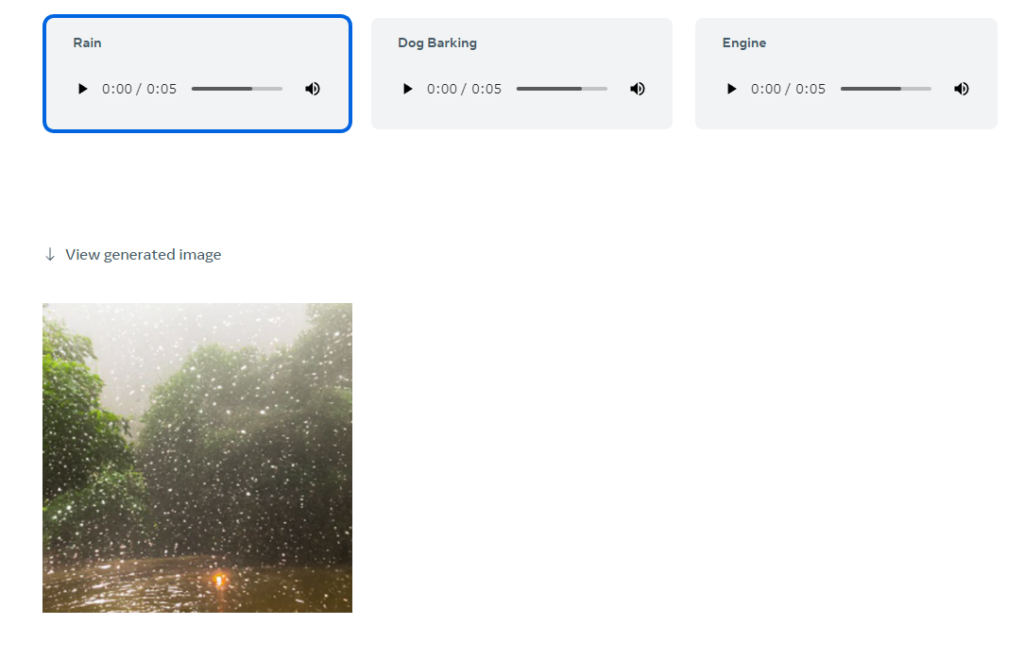
音から画像を生成します。ジェネレイトということで、完全なAIGCです。
まとめ
Meta社もAI分野で存在感を増してきています。GAFAMのPJということで、AI分野でビジネスをしている方々にとっては重要な情報となります。ぜひチェックしておきましょう。
本サイトではWeb3、AI、XRの最新情報を発信しています。ぜひサイト登録お願いいたします。あわせて、適時性のある情報はTwitterでTweetしています。@suzuki_sato_funフォローも何卒よろしくお願いいたします。


コメント